| Page 3 out of 51 Pages ... Showing Questions in Random order from Exam |
A consultant is setting up a new install of Nutanix Files for a customer, but receives this error when attempting to join the customer's Active Directory domain: File Server could not join the Domain because User credentials failed with error Unable to connect to WORKGROUP ads_connect: No logon servers The consultant has already verified the domain credentials provided by the customer are valid and have the correct permissions. What is the most likely cause in this scenario for a domain-join failure when setting up Nutanix Files?
A. The FSVMs storage network must be in the same network as the logon servers.
B. The client network is failing to communicate with the customer's domain controllers due to mismatched MTU sizes
C. The client network is failing to communicate with the customer's domain controllers due to a missing network firewall port requirement.
D. The FSVMs must first be manually added to a site mapping in Active Directory before they can be authorized to communicate with the logon servers.
Refer to the exhibit.
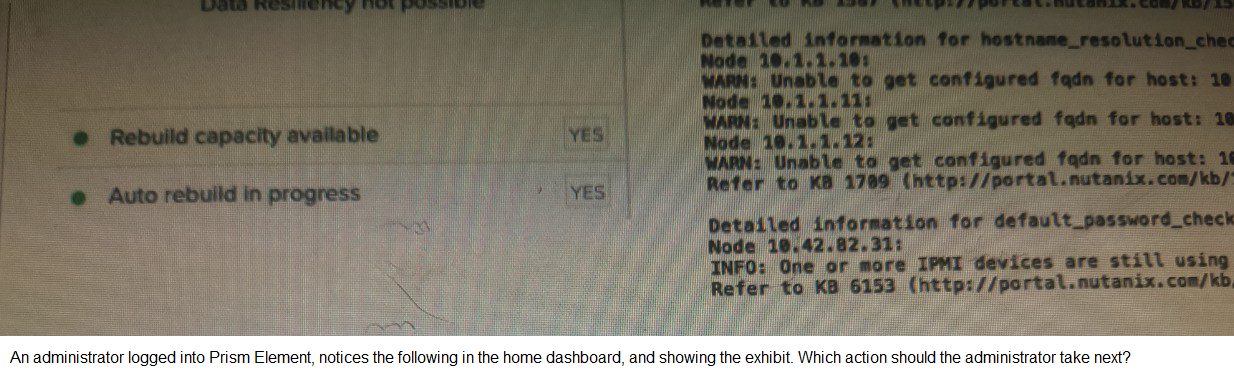
A. Configure the fqdn for the hosts indicated
B. Troubleshoot the zookeeper server issue
C. Re-run NCC specifying data_resiliency_check
D. Check the hardware page for disk failures
Explanation: The exhibit shows a screenshot of a Prism Element home dashboard with a notification that “Data Resiliency not possible” and warnings about the inability to get configured fully qualified domain names (fqdn) for hosts identified by their node numbers. In this scenario, the administrator should take action A: Configure the fqdn for the hosts indicated. This is because the warnings on hostname resolution indicate issues with fully qualified domain names (fqdn) configuration for specific nodes. Configuring the fqdn for these hosts can help resolve these issues and improve the data resiliency of the Nutanix cluster1.
An administrator receives an alert in Prism indicating that interface eth2, on an AHV host is
receiving many CRC errors. After togging into the problematic host, the following command
is run to show the indicated output: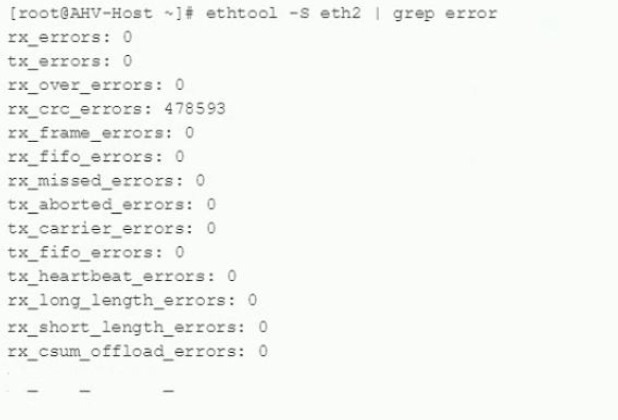
What is causing this issue?
A. Incorrect link speeds on the switch
B. The interface is incorrectly configured with Jumbo Frames
C. A misconfigured bond
D. A physical layer network problem
Explanation: Ref: rx_crc_errors are caused either by faults in layer 1 (in the past, we have seen failed twinax cables and incorrect types of fibre being used), or issues with jumbo frames on the network. In an environment with 10 Gig switches that use cut-through forwarding (Cisco Nexus, Arista, Cisco devices using IOS default to Store and Forward switching), any packets that come into the switch will get forwarded out the destination interface once the switch has read the destination MAC address. If that packet has an MTU over what is configured on the interface, it will cut off the packet at the designated MTU, causing the server to receive a malformed packet, which will throw a CRC error. If you have a layer 1 issue, you will see rx_crc_errors, not on all but one or two nodes.
Refer to Exhibit: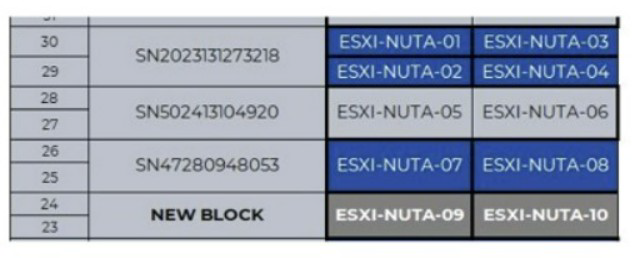
A customer is preparing to expand a cluster with a consultant. The production cluster is
comprised of one NX-3460-G7 and two NX-8235 G8 blocks. The running AOS version is
5.20.4.6 and Hypervisor version is ESXi 6.7 U3b. vCenter is also running a 6.7 version.
One NX-3235-G9 block will be added to that cluster (ESXI-NUTA-09 and ESXI-NUTA-10).
The consultant has verified Nutanix documentation and customer’s As-Built guide:
•NX-3060-G7 and NX-8035-G8 are hybrid HCI nodes
•ESXi 6.7 U3b is unsupported for the new G9 hardware model
•AOS 5.20.X and ESXi 6 X are end of support
•NX-3060-G7 and NX-8035-G8 hypervisors can be upgraded to the latest ESXi supported
version
What actions should be taken before beginning the cluster expansion?
A. Upgrade vCenter, AOS and ESXi to supported and recommended versions.
B. Upgrade only AOS and ESXi to supported and recommended versions.
C. Replace all HDDs with SSDs on the Production cluster.
D. Prepare Foundation and the whitelist. json file to deploy ESXi 6.7 U3b on the new nodes.
Explanation: Before expanding the cluster with the new NX-3235-G9 block, it is critical to ensure that all components are running supported and recommended versions due to compatibility and support issues. Therefore, the necessary actions include: A. Upgrade vCenter, AOS, and ESXi to supported and recommended versions. This step ensures compatibility across all components, particularly important as the new G9 hardware does not support the currently installed version of ESXi. Upgrading these components will also ensure continued vendor support and the stability of the environment. Options B, C, and D do not adequately address the need for vCenter upgrades or the fact that ESXi 6.7 U3b is unsupported for G9, highlighting the necessity for a comprehensive upgrade.
During Foundation, all nodes are imaged successfully. The cluster creation step fails. The consultant troubleshoots the issue and verifies that all Hosts and CVMs are up and running and responding to network pings. Which method should the consultant select to create the cluster?
A. Log into one of the hosts and run the cluster create command.
B. Image the Bare Metal nodes.
C. Log into one of the CVMs and run the cluster create command.
D. Factory reset the nodes and re-start the Foundation process.
Explanation: After confirming that all nodes (Hosts and CVMs) are operational and network accessible, the next step in troubleshooting a failed cluster creation process is to use one of the CVMs to manually initiate the cluster creation. This is done using the command cluster create from a CVM, which allows you to establish the cluster management and data services provided by Nutanix. This approach is recommended when the Foundation process has successfully imaged the nodes but the automatic cluster creation has failed.
A customer has a Nutanix cluster with 10Gb connectivity via switch fabric extenders. The administrator receives NCC health check errors of latency greater than 200ms. Which action should the administrator take to resolve the NCC errors?
A. Replace the switch fabric extenders with 10G line rate switches
B. Upgrade NCC and increase the CVM memory by 4Gb
C. Add 2 additional 10G uplinks from the switch fabric extenders per node
D. Upgrade NCC and increase the vCPU of the CVM
| Page 3 out of 51 Pages |
| Previous |
Contact Us - Privacy Policy - Refund Policy - Terms ... Copyright © - All Rights Reserved